JungMok LeeI am a 1st-year Ph.D. student at AMI Lab, where I work on multimodal perception, advised by Tae-Hyun Oh. I major in Department of Electrical Engineering at KAIST. I'm interested in computer vision, multimodal large language model, machine learning, and visual interpretation. |

|
Publications & Research |

|
SMILE-Next: Teaching Large Language Models to Detect, Classify, and Reason about LaughterLee JungMok, Kim Sung-Bin, Joohyun Chang, Lee Hyun, Tae-Hyun Oh ACL 2026 [project page] [arxiv] [code] We introduce the SMILE-NEXT, a comprehensive corpus combining audio, visual, and textual cues for laughter understanding across diverse contexts. We propose Laugh Expert MOE architecture, a lightweight yet expressive model architecture to efficiently model laughter perception. |
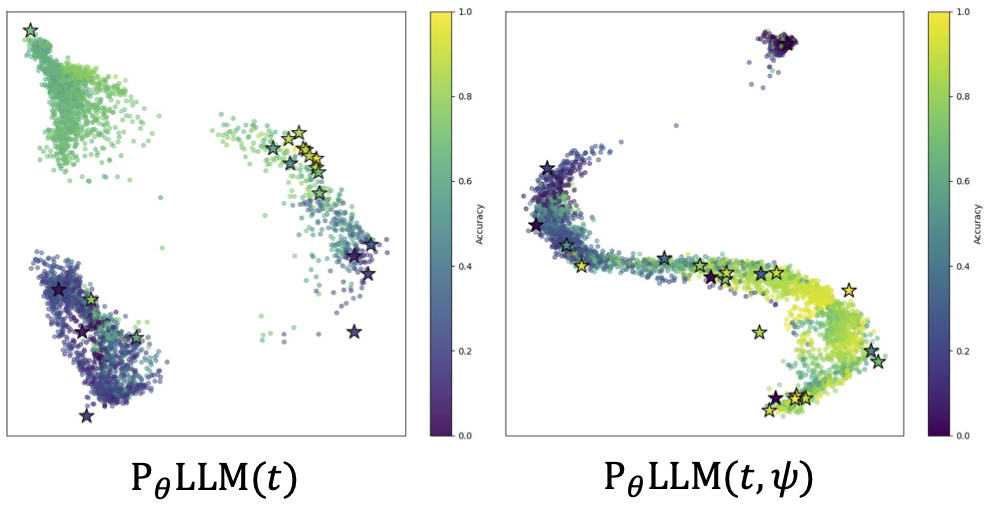
|
A Language-Guided Bayesian Optimization for Efficient LoRA Hyperparameter SearchBaek Seong-Eun, Lee Jung-Mok, Kim Sung-Bin, Tae-Hyun Oh ICML 2026 [project page] [arxiv] We present an approach that integrates LLMs with Bayesian Optimization to efficiently tune LoRA hyperparameters. This method enables adaptive search over the hyperparameter space, improving fine-tuning performance and computational efficiency. |
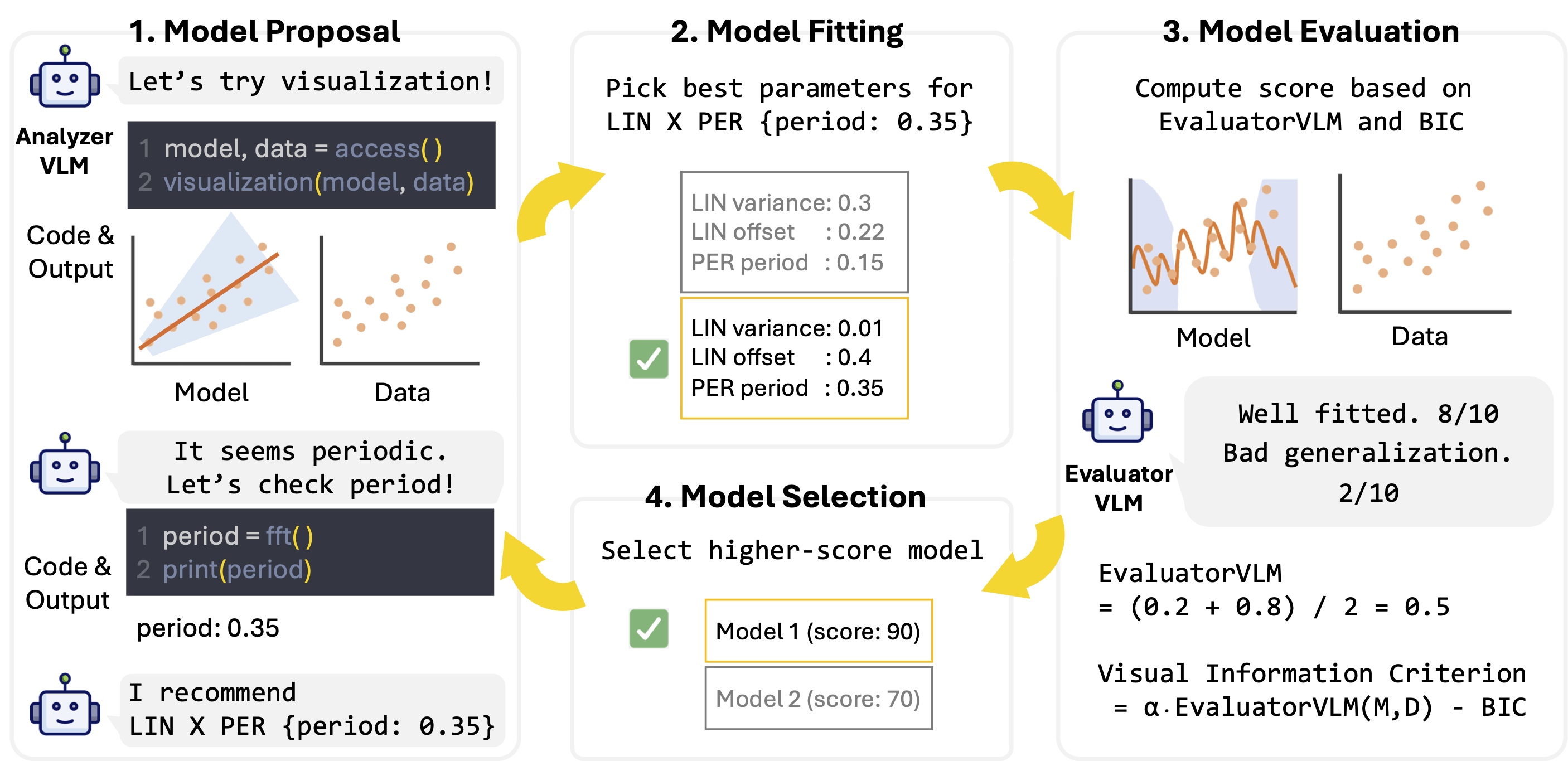
|
Automated Model Discovery via Multi-modal & Multi-step PipelineLee Jung-Mok, Nam Hyeon-Woo, Moon Ye-Bin, Junhyun Nam, Tae-Hyun Oh NeurIPS 2025 [project page] [arxiv] [code] We present a multi-modal & multi-step pipeline for effective automated model discovery, using the multimodal LLM agents. We model the interpretation of time-series data using Gaussian Process kernel discovery. |
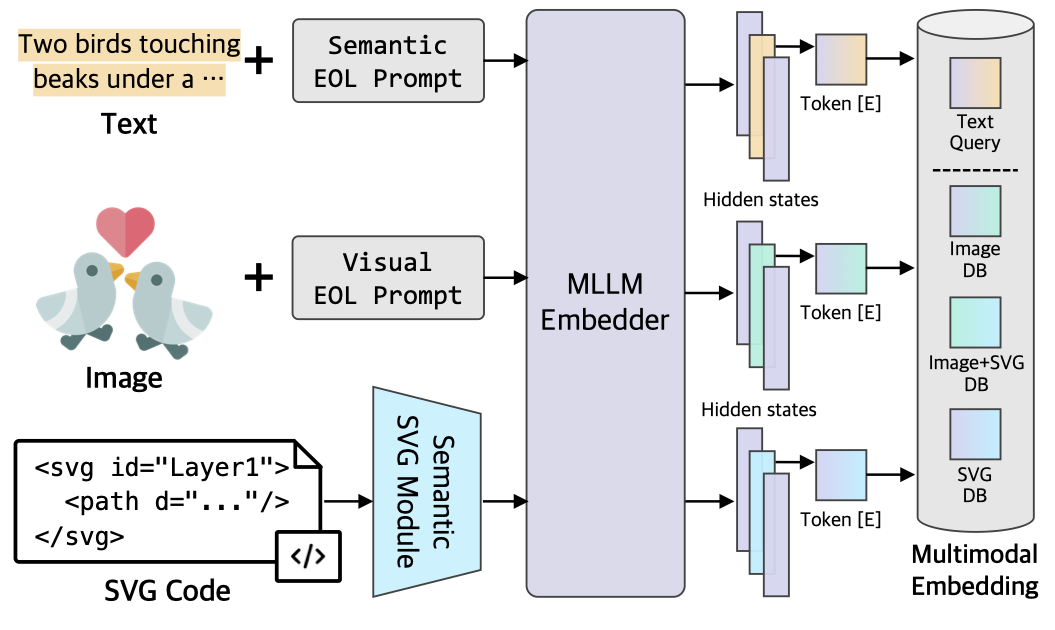
|
Training-free Multimodal Embedding for Structure-Aware Retrieval of Scalable Vector Graphics and ImagesKyeongseon Kim, Baek Seong-Eun, Lee Jung-Mok, Tae-Hyun Oh WACV 2026 [project page] [arxiv] [code] We propose the first training-free multimodal embedding method that uses a Multimodal Large Language Model (MLLM) to project text, images, and SVG code into an aligned space. |

|
AVHBench: A Cross-Modal Hallucination Benchmark for Audio-Visual Large Language ModelsKim Sung-Bin*, Oh Hyun-Bin*, Lee Jung-Mok, Arda Senocak, Joon Son Chung, Tae-Hyun Oh ICLR 2025 [project page] [arxiv] [code] We introduce a comprehensive audio-visual hallucination benchmark specifically designed to evaluate the perception and comprehension capabilities of audio-visual LLMs. |
|
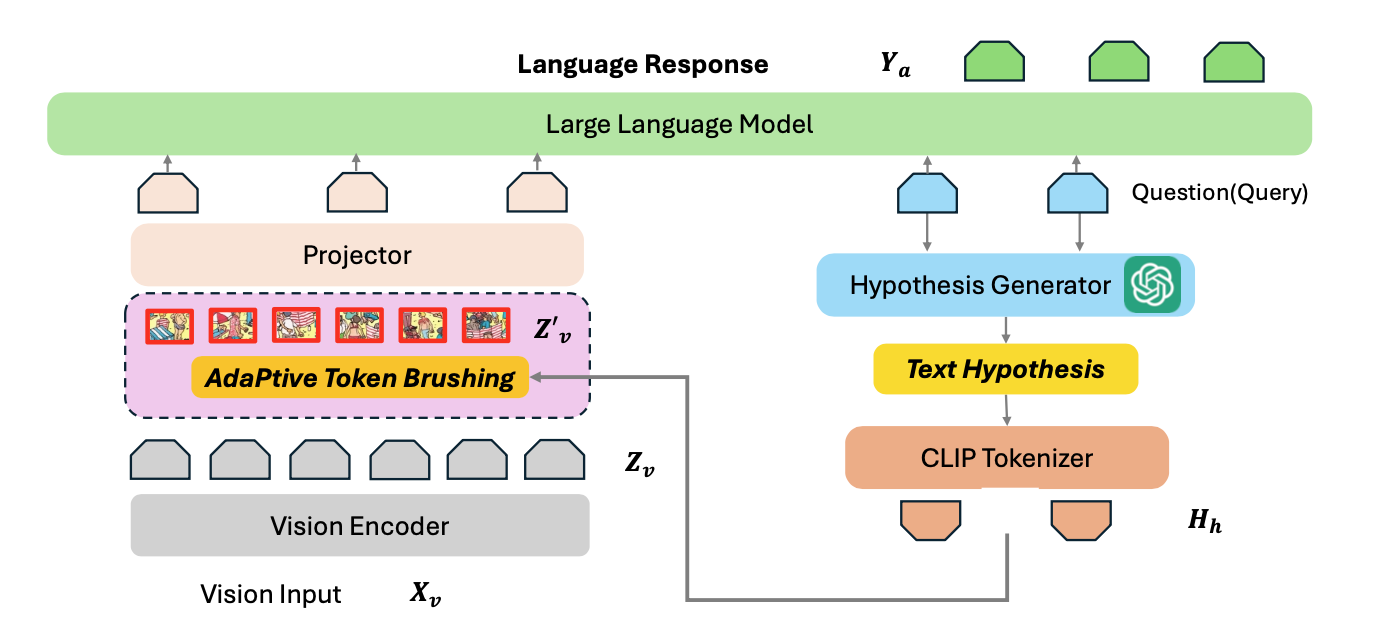
GOAT: Goal-Oriented Adaptive Token pruning for Large Vision-Language ModelsWonseok Choi, Lee Jung-Mok, Tae-Hyun Oh IPIU 2025 We introduce GOAT, Goal-Oriented Adaptive Token pruning, a dynamic framework for selective token pruning. GOAT utilizes contextual hypotheses and confidence scores to identify and retain task-relevant visual tokens through an adaptive Token Brushing process. |
|
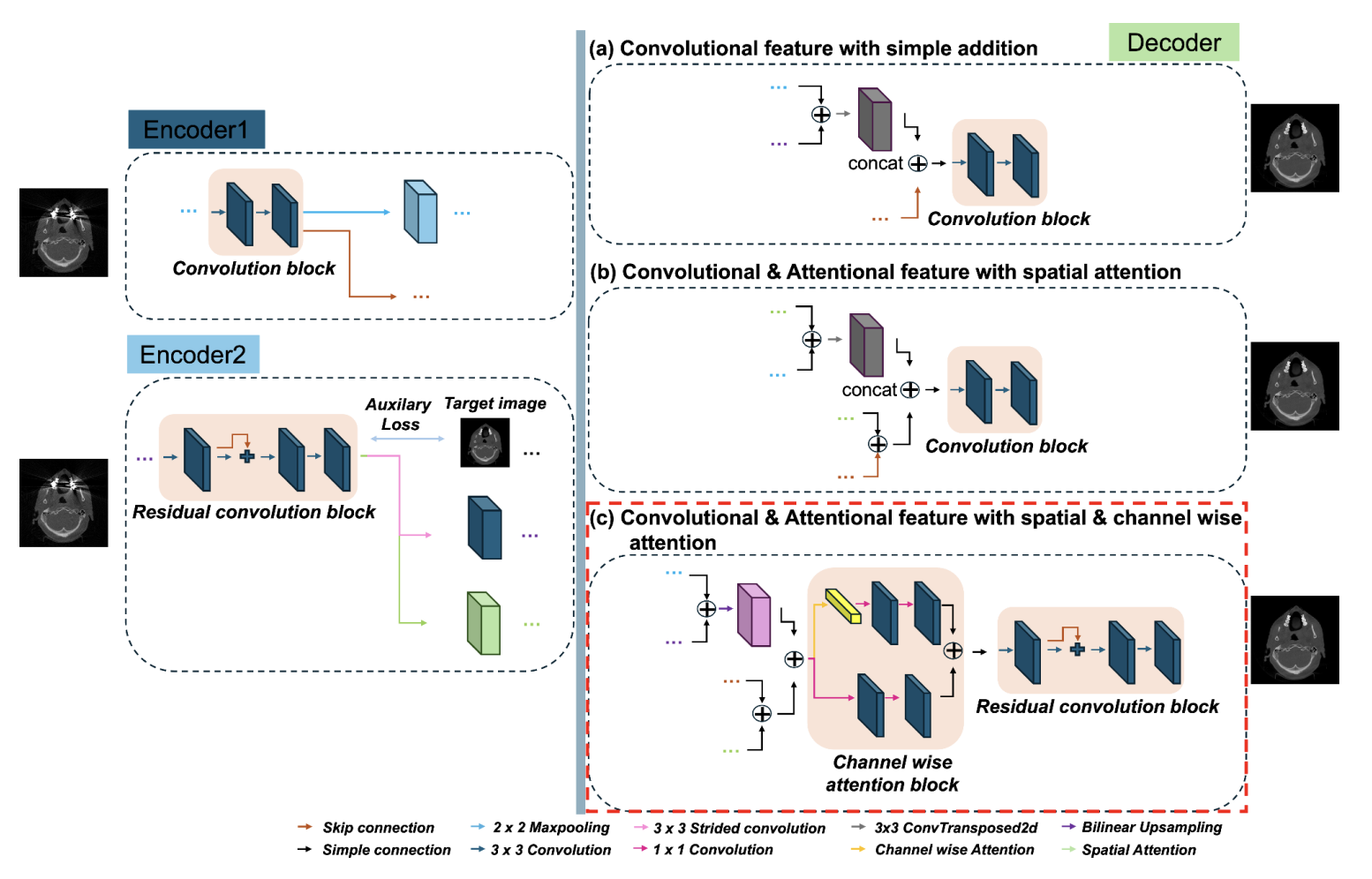
Metal Artifact Reduction for Head and Neck CBCT with Attentional Dual Encoder Fusion UNetLee Jung-Mok, Lee Wonjin, Ki Juhyeong, Kim Bitbyeol, Jung Seongmoon, Lee Jimin RSNA 2023 [arxiv] We propose attention-based dual encoder UNet to effectively remove the metal artifact at CBCT image. Each encoder uses spatial & channel-wise attention with the auxilary loss to effectively recover the overall structure and to remove the metal artifacts. |
|
Design and source code from Jon Barron's website |